The TianGong-CRL Dataset
We provide this Chinene-centric TianGong-CRL dataset to support researches in epidemic related Information Retrieval (IR) tasks and information needs of Chinese people in the context of COVID-19. Refined from an 82-day search log by Sogou, the second largest search engine in China, the dataset consists of two parts: the first part provides a collection of 1492 COVID-19 related queries and the submission frequency of these queries in each province of China over an 82-day period, the second part provides a sample of COVID-19-related search logs during the period, we only provide session-level data for user privacy concerns. We also sample a subset of 1,700 sessions from TianGong-CRL and manually label each session with five intent labels.
TianGong-CRL数据集可用于传染病相关的信息检索任务的研究和COVID-19疫情背景下的中国搜索引擎用户信息需求研究。该数据集从一份长达82天的搜狗搜索用户日志中提取,数据集包含两个部分:第一个部分提供了由1492个查询组成的传染病相关查询集合和82天内中国各省份这1492个查询的提交频次;第二个部分提供了疫情期间内部分用户的相关搜索日志,考虑到用户的隐私问题,我们只提供会话级别数据。此外,我们也从 TianGong-CRL中抽取了1700个会话的样本,用5个搜索意图标签标记了每个会话。
Motivation
COVID-19 was discovered by the end of 2019 and spread globally with a strong capacity for infection, causing incalculable damage to human health and the social economy. Chinese search engine users are among the first ones to generate millions of related search records due to the early impact of the epidemic.
2019年底,新冠肺炎被发现并在全球传播,感染能力强,对人类健康和社会经济造成不可估量的损害。由于较早的疫情影响,中国搜索引擎用户已经产生了相当规模的疫情相关搜索记录。
Previous studies built connection between Internet activity and the development of an epidemic. The search log data during the epidemic contains rich user behaviors. It can give us new insights into the information needs of Chinese people in the context of COVID-19, and further improve the performance of search engines[3] and the prediction of the epidemic[1,2]. However, there is a lack of proper dataset during a special epidemic. Considering the aforementioned issues, we provide this large-scale refined COVID-19-related query log benchmark.
近年来,有很多的研究表明了互联网用户行为和流行病发展之间的联系。疫情期间的搜索日志数据包含丰富的用户行为。这些数据可以帮助我们了解中国搜索引擎用户在疫情背景下的用户需求,并进一步提高搜索引擎的性能[3]和对于疫情的预测能力[1,2]。然而,目前还缺少特殊疫情期间的搜索日志数据集记录。 基于以上考虑,我们发布了一份全新的大规模COVID-19相关搜索日志数据集来支持相关的研究工作。
Dataset Description
The TianGong-CRL dataset is extracted from a query log collected by Sogou.com. The dataset consists of two parts. The first part consists of a COVID-19-related query set(*.csv), a COVID-19-related query frequency data(*.csv) and a total frequency data(*.csv). The COVID-19-related query set is generated from the graph propagation algorithm based on the click bipartite graph[1]. The COVID-19-related query frequency data contains 82 days(from January 1, 2020 to March 22, 2020) search frequency of 1492 COVID-19-related queries in China’s 34 provinces. For data normalization, we also provide total query frequency data(including irrelevant queries submitted in Sogou) in selected 6 days.
TianGong-CRL是从一份搜狗日志中提取的数据集。该数据集分为两个部分。第一个部分包括一份新冠相关查询集合(*.csv),一个新冠相关查询频率集合(*.csv)和一个总查询频率集合(*.csv)。新冠相关查询集合基于点击二部图上的图传播算法得到[1]。新冠相关查询频率数据包含中国34个省份中1492个新冠相关查询在82天(2020年1月1日至2020年3月22日)内的搜索频率。为了数据归一化,我们同时提供了期间6天内各省的总体查询频率数据(包括新冠相关和非相关查询的提交频率)。
The second part consist of a sample of COVID-19-related session data(*.xml) and a human label file(*.csv). The session data contains 97,971 sessions, 151,232 queries and 118,502 clicks. The raw log data contains abundant Web search sessions mingled with noise. Therefore, it is hard to directly employ it for research purpose. To tackle the issue, we refine the sessions by filtering sessions which contain pornographic, violent or politically sensitive contents, removing sessions with more than 15 queries. Then, we generate a manual-rule-based model to identify a session’s relevancy to COVID-19 and remove the irrelevant sessions.
第二个部分包括一份新冠相关的会话级搜索日志集合和一份人工标注的会话搜索意图文件。会话级搜索数据集包含97,971个搜索会话,151,232个查询和118,502次点击。原始的日志数据包含噪音,难以直接用于研究。为此,我们通过过滤包含色情暴力和政治敏感词的会话, 去掉提交查询数目超过15的会话等方法将数据进行了初步清洗和提炼。然后,我们设计了一个基于手动规则的模型来识别会话与COVID-19的相关性,并删除不相关的会话。
To be specific, we segment 1492 COVID-19-related queries into terms, manually select hundreds of COVID-19-related terms and obtain search sessions containing at least one of these terms. To obtain a more accurate dataset, we label 1,200 queries (split into train set and valid set) and design manual rules(manual rules are designed by matching against special keywords that generate from training set) to identify its relevancy to COVID-19. The recall of our manual-rule-based model in valid set achieves 91%.
具体来说,我们将1492个新冠相关查询分割成词语,从中人工选择数百个新冠相关词语并提取所有包含这些词语的搜索会话。为了提高数据集的准确性,我们对于1200个查询进行了标注(分成训练集和验证集),并设计手工规则(手工规则是通过基于训练集数据提取特殊关键字来设计的)以识别其与COVID-19的相关性。基于手工规则的模型在验证集的召回率达到91%。
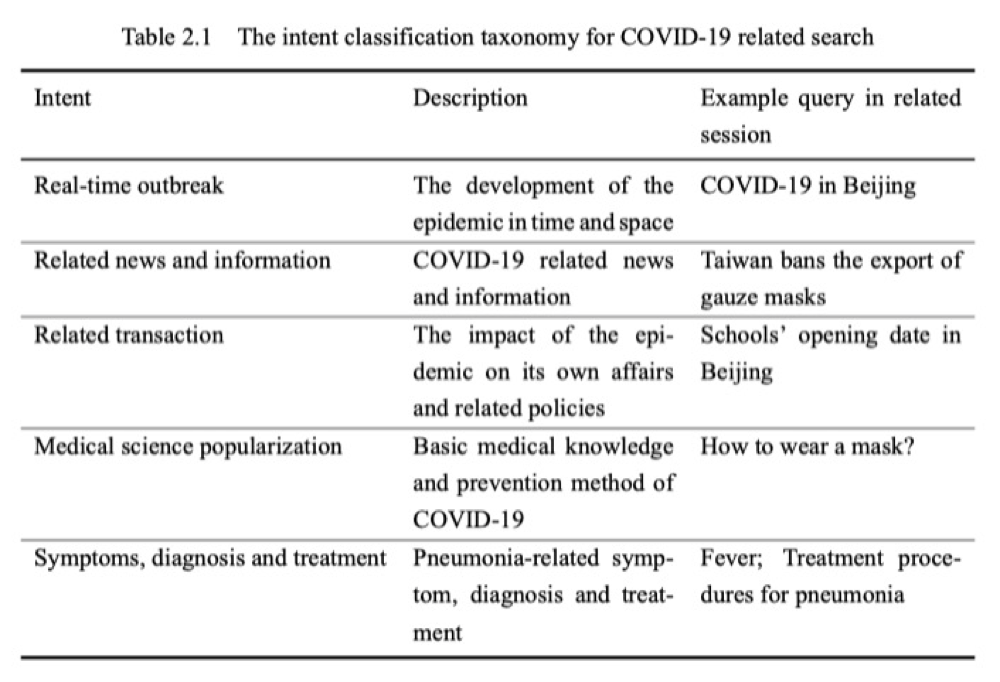
In addition, we manually label 1,700 sessions with five labels(see Table 2.1). Labels are not mutually exclusive and each of them is a binary decision. Based on these annotated data, we design deep learning model to predict intent labels of our dataset.
此外,我们用5个标签手工标注1,700个会话(见表2.1)。标签不是相互排斥的,每个标签都是二元的决定。基于这些标注的数据,我们利用深度学习模型预测了数据集中每个搜索会话的意图标签。
Dataset Organization
For the first part of data, the COVID-19-related query frequency data contains the search frequency(from q0 to q1491) in different date(eg. 0101) and province(eg. 湖北省). The COVID-19-related query set provides query id as well as query text, corresponding to the query id in the frequency file. The total frequency file provides total query frequency in Sogou in different province.
对于第一部分数据,COVID-19相关查询频率数据包含不同日期(如0101)和不同省份(如湖北省)的搜索频率(从q0到q1491)。COVID-19相关查询集合提供查询id及其查询文本,与频率文件中的查询id相对应。总查询频率文件提供不同省份在Sogou上的总查询频率。
The session data in the second part is organized in a prettified XML format similar to TREC Session Tracks, as shown in the following.
TianGong-CRL的会话数据按照类似TREC Session Tracks组织为XML格式,如下所示:
<?xml version="1.0" encoding="utf-8"?>
<SogouSessionTrack2020>
<session num="2" starttime="1580964053">
<interaction num="0" starttime="1580964053">
<query>疫情行业大清洗,之后做什么生意</query>
<results>
<result_rank>1</result_rank>
<url>https://www.haoz.net/zatan/remenshijian/133708</url>
<cilcked_time>1580964061</cilcked_time>
</results>
</interaction>
<interaction num="1" ...>
...
</interaction>
...
<predict_labels>
<Real-time outbreak>0</Real-time outbreak>
<Related news and information>0</Related news and information>
<Related transaction>1</Related transaction>
<Medical science popularization>0</Medical science popularization>
<Symptoms, diagnosis and treatment>0</Symptoms, diagnosis and treatment>
</predict_labels>
</session>
...
</SogouSessionTrack2020>
A session is consist of several search interactions together with a clicked-document list. Each interaction represents a search iteration where a user submits an independent query and clicks documents from the search engine. In addition, the start timestamps for all sessions, interactions, and clicked documents are also presented to support dwell-time based models.
一个会话由多个交互以及一个被点击的文档列表组成。每个交互表示会话中的一个回合:用户提交一个查询,并点击搜索引擎返回的相关文档。另外,我们还提供了所有会话、交互回合以及被点击文档的开始时间戳,以便支持基于停留时间的模型。
As for the human label file, it contains up to 15 queries submitted in a session(from q0 to q14), the relevance label and the intent labels(1 means relevant and 0 means irrelevant).
对于人工标注的文件,它包含在一个会话中提交的最多15个查询(从q0到q14),关联标签和意图标签(1表示相关,0表示不相关)。
How to get TianGong-CRL
To gain access to the TianGong-CRL dataset, you need to contact with us (thuir_datamanage@126.com). After signing an application forum online, we can send you the data. If there is any problem with our dataset, please feel free to contact us.
若希望获取TianGong-CRL的数据,请通过邮件联系我们(thuir_datamanage@126.com),在完成在线申请后即可获得。如果我们的数据有任何问题,请随时与我们联系。
Reference
[1] XU D, LIU Y, ZHANG M, et al. Predicting epidemic tendency through search behavior analysis[C/OL]//WALSH T. IJCAI 2011, Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, July 16-22, 2011. IJCAI/AAAI, 2011: 2361-2366. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-393.
[2] GINSBERG J. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457.
[3] White, R. W., & Horvitz, E. (2013). Captions and biases in diagnostic search. ACM Transactions on the Web (TWEB), 7(4), 1-28.
[4] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.