The Tiangong-ULTR Dataset
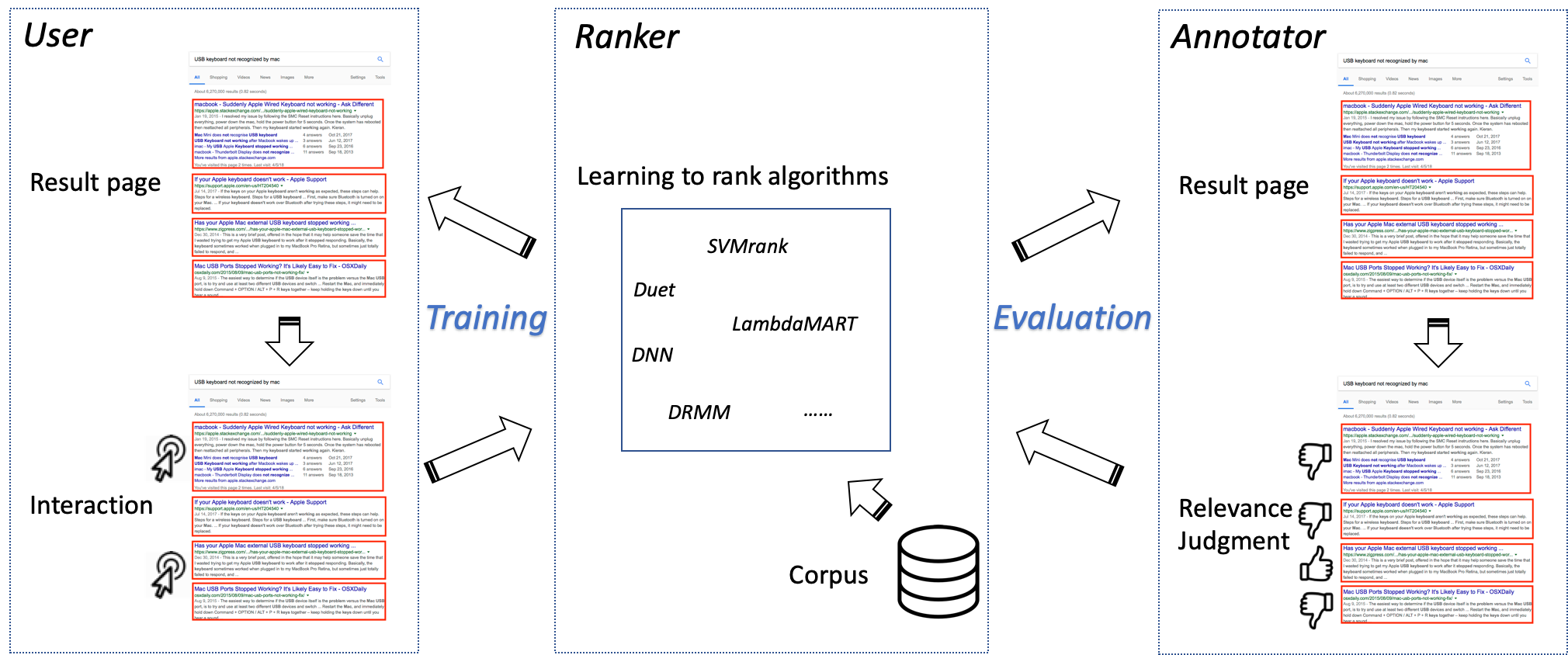
The Tiangong-ULTR (Unbiased Learning To Rank) dataset is constructed to support the studies on unbiased learning to rank. Implicit feedback such as clicks are the most important data source for ranking systems in practice such as search engines and recommendation systems. Unfortunately, training a ranking model to optimize click data is infeasible because click data are heavily biased due to a variety of factors including but not restricted to result positions, sources, etc. To build and evaluate unbiased learning to rank algorithms, one need to train the model with biased supervision signals while testing the model with unbiased human-annotated labels. In order to facilitate the research on this topic, this dataset provides real click data sampled from the search logs of Sogou.com for the training of unbiased learning to rank algorithm as well as a seperate set of human-annotated data for the evaluation of their performance.
Data Statistics
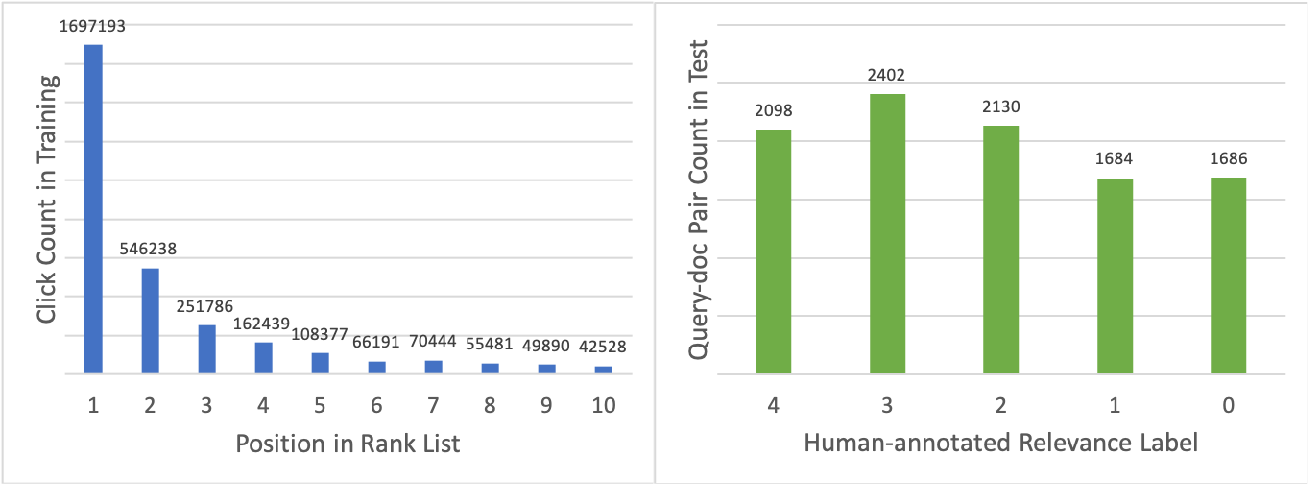
This dataset consists of two parts. The first part is a training set with 3,449 queries written by real search engine users and the corresponding top 10 results sampled from a two-week search log collected on Sogou.com. Each query has appeared in at least 10 sessions with clicks in the sampled search logs. The second part is a test set used in the NTCIR-14 We Want Web Task with 100 queries (written by real users). Each query has 100 candidate documents (retrived by BM25) and each query-document pair has 5-level relevance annotation from 0 to 4 (irrelevant, fair, good, excellent and perfect). We downloaded the raw HTML documents based on urls and removed ranked lists which contain documents that cannot be reached by our crawler. After cleaning, we have 333,813 documents, 71,106 ranked lists and 3,268,177 anonymized search sessions with clicks in total.
All documents are represented with feature vectors so that the dataset can be directly used in the task of unbiased learning to rank. The ranking features are constructed based on the url, title, content and whole text of the documents and queries. In total, each query-document pair has 33 features. More information about the ranking features can be found below and our paper at SIGIR 18.
| Data | Train | Test |
|---|---|---|
| #Query | 3,449 | 100 |
| #Document | 333,813 | 10,000 |
| #Rank List | 71,106 | 100 |
| #Session | 3,268,177 | 100 |
| Label | clicked (0) or not (1) | 5-level relevance annotations (0-4) |
Data Instructions
The files and directories contained in Tiangong-ULTR are shown below. The dataset is totally about 42 MB in size when compressed.
| File or Directory | Data |
|---|---|
| settings.json | Some basic information about the dataset. |
| train/ | The directory of the training data. |
| train/train.feature | The file of the ranking features for all training query-document pairs. |
| train/train.init_list | The file of ranked lists used to collect user clicks online. |
| train/train.labels | The file of click labels for each list in train.init_list. |
| test/test.feature | The file of the ranking features for all test query-document pairs. |
| test/test.init_list | The file of candidate document lists for each query (ordered randomly). |
| test/test.labels | The file of human-annotated relevance labels for each document in test.init_list. |
train/train.feature:
<doc_id> <feature_id>:<feature_val> <feature_id>:<feature_val> ... <feature_id>:<feature_val>
<doc_id> = the identifier of the query-document pair.
<feature_id> = an integer identifier for each feature from 0 to 699
<feature_val> = the real feature value
Each line represents a different query-document pair.
train/train.init_list:
<query_id> <feature_line_number_for_the_1st_doc> <feature_line_number_for_the_2nd_doc> ... <feature_line_number_for_the_Nth_doc>
<query_id> = the integer identifier for each query.
<feature_line_number_for_the_Nth_doc> = the line number (start from 0) of the feature file (train.feature) in which the features of the Nth document for this query is stored.
Each line represents a rank list for a query. Documents are represented with their line number in train.feature, and are sorted based on their positions online.
train/train.labels:
<query_id> <click_label_for_the_1st_doc> <click_label_for_the_2nd_doc> ... <click_label_for_the_Nth_doc>
<query_id> = the integer identifier for each query.
<click_label_for_the_Nth_doc> = the human annotated relevance value of the Nth documents in the initial list of the corresponding query. For 5-level relevance judgments, it should be one of the value from {0,1,2,3,4}.
Each line represents a list of click labels (0 for not clicked and 1 for clicked) for the documents in the corresponding line in train.init_list.
test/test.feature:
<doc_id> <feature_id>:<feature_val> <feature_id>:<feature_val> ... <feature_id>:<feature_val>
<doc_id> = the identifier of the query-document pair.
<feature_id> = an integer identifier for each feature from 0 to 699
<feature_val> = the real feature value
Each line represents a different query-document pair.
test/test.init_list:
The rank lists for each query:
<query_id> <feature_line_number_for_the_1st_doc> <feature_line_number_for_the_2nd_doc> ... <feature_line_number_for_the_Nth_doc>
<query_id> = the integer identifier for each query.
<feature_line_number_for_the_Nth_doc> = the line number (start from 0) of the feature file (test.feature) in which the features of the Nth document for this query is stored.
Each line represents a candidate document list for a query. Documents are represented with their line number in test.feature, and are sorted randomly.
test/test.labels:
<query_id> <relevance_value_for_the_1st_doc> <relevance_value_for_the_2nd_doc> ... <relevance_value_for_the_Nth_doc>
<query_id> = the integer identifier for each query.
<relevance_value__for_the_Nth_doc> = the human annotated relevance value of the Nth documents in the initial list of the corresponding query. For 5-level relevance judgments, it should be one of the value from {0,1,2,3,4}.
Each line represents a list of human-annotated relevance labels (0 for not clicked and 1 for clicked) for the documents in the corresponding line in test.init_list.
How to get Tiangong-ULTR
The dataset can be downloaded here.
Citation
If you use Tiangong-ULTR in your research, please add the following bibtex citation in your references. A preprint of this paper can be found here.
@inproceedings{Ai:2018:ULR:3269206.3274274,
author = {Ai, Qingyao and Mao, Jiaxin and Liu, Yiqun and Croft, W. Bruce},
title = {Unbiased Learning to Rank: Theory and Practice},
booktitle = {Proceedings of the 27th ACM International Conference on Information and Knowledge Management},
series = {CIKM '18},
year = {2018},
isbn = {978-1-4503-6014-2},
location = {Torino, Italy},
pages = {2305--2306},
numpages = {2},
url = {http://doi.acm.org/10.1145/3269206.3274274},
doi = {10.1145/3269206.3274274},
acmid = {3274274},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {click model, counterfactual learning, unbiased learning to rank, user bias},
}
@inproceedings{Ai:2018:ULR:3209978.3209986,
author = {Ai, Qingyao and Bi, Keping and Luo, Cheng and Guo, Jiafeng and Croft, W. Bruce},
title = {Unbiased Learning to Rank with Unbiased Propensity Estimation},
booktitle = {The 41st International ACM SIGIR Conference on Research \&\#38; Development in Information Retrieval},
series = {SIGIR '18},
year = {2018},
isbn = {978-1-4503-5657-2},
location = {Ann Arbor, MI, USA},
pages = {385--394},
numpages = {10},
url = {http://doi.acm.org/10.1145/3209978.3209986},
doi = {10.1145/3209978.3209986},
acmid = {3209986},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {inverse propensity weighting, learning to rank, propensity estimation},
}