The TianGong-ST Dataset
We provide this Chinese-centric TianGong-ST dataset to support researches in a wide range of session-level Information Retrieval (IR) tasks. Refined from an 18-day search log by Sogou, the second largest search engine in China, the dataset consists of 147,155 refined Web search sessions, 40,596 unique queries, 297,597 Web pages, and six kinds of weak relevance labels assessed by click models. We also sample a subset of 2,000 sessions from TianGong-ST and collect 5-level human relevance labels for documents of the last queries in them.
TianGong-ST数据集可广泛用于会话级别信息检索任务的研究。该数据集从一份长达18天的搜狗搜索用户日志中提取,共包含了147155个搜索会话、40596条不重复的查询、297597个网页正文以及使用6种常用点击模型自动标注的文档弱相关性标签。另外,我们还采样了一个包含2000个会话内容的数据子集,收集并提供了这些会话中最后一个查询下的所有文档的5级人工相关性标签。
Motivation
Recently, numerous studies have shown great advantages of considering the context information in various IR tasks such as session search, query suggestion, and etc. However, the lack of proper dataset limits the progress of related research. There are few test collections available for session-level IR research. Among them, TREC Session Tracks, running from 2011 to 2014, are the most widely applied datasets. They provide test collections with various forms of implicit feedbacks as well as human relevance labels for participants to optimize document ranking performance for the last query in a session. However, these tracks are mainly collected via user studies or crowdsourcing experiments with simulated search tasks. Therefore, they may not necessarily represent real-world Web search scenarios and only contain tens to thousands sessions that are usually deficient for more sophisticated models. Besides, the large-scale AOL search log is collected from real users, but it is noisy and outdated (a certain proportion of URLs are no longer accessible). Considering the aforementioned issues, we provide this large-scale refined session benchmark.
近年来,有很多的研究表明在各种信息检索任务中引入上下文因素可以更好地提升系统性能, 例如会话搜索任务、查询推荐任务等等。然而,由于缺少相应合理的数据集限制了相关研究的进展。在已有的数据集中,2011-2014年由TREC Session Tracks提供的会话数据集被学术界广泛地使用。Session Tracks 提供了具有各种用户反馈信息的会话数据以及人工标注相关性标签,以使参赛者能够利用这些信息来改进会话中最后一个查询下的文档排序性能。然而这些会话数据主要是通过基于模拟搜索任务的用户实验或者众包实验收集的,数据量较小且不能反映真实的用户搜索场景。 另外,从真实用户中收集的大规模AOL日志数据,其发布年代较为久远,还包含许多噪音。 基于以上考虑,我们发布了一份全新的大规模会话数据集来支持相关的研究工作。
Dataset Description
The TianGong-ST dataset is extracted from a query log collected by Sogou.com. This dataset consists of a XML-formated session data (*zip, about 1.5GB), a crawled Web page set (*zip, about 1.95BG) and a human label file (*txt, 542KB).
TianGong-ST是从一份搜狗日志中提取的数据集,包含一份XML格式的会话数据(zip,约1.5GB)、一份抓取网页集合(zip,约1.95GB)以及一份人工标注的相关性文件(txt,542KB)。
The raw log data contains abundant Web search sessions mingled with noise. Therefore, it is hard to directly employ it for research purpose. To tackle the issue, we refine the sessions through a series of procedures and filter the noisy data step by step. These steps include filtering sessions which contain pornographic, violent or politically sensitive contents, removing sessions with long-tailed queries, discarding sessions without any clicks, and etc. More details can be found in the corresponding paper.
原始的日志数据包含噪音,难以直接用于研究。为此,我们通过一系列步骤将数据进行清洗和提炼。这些步骤包括:过滤包含色情、暴力和政治敏感词的会话, 去掉包含稀有查询的会话以及过滤不含任何点击的会话等等。更多详细操作请参见相应的论文。
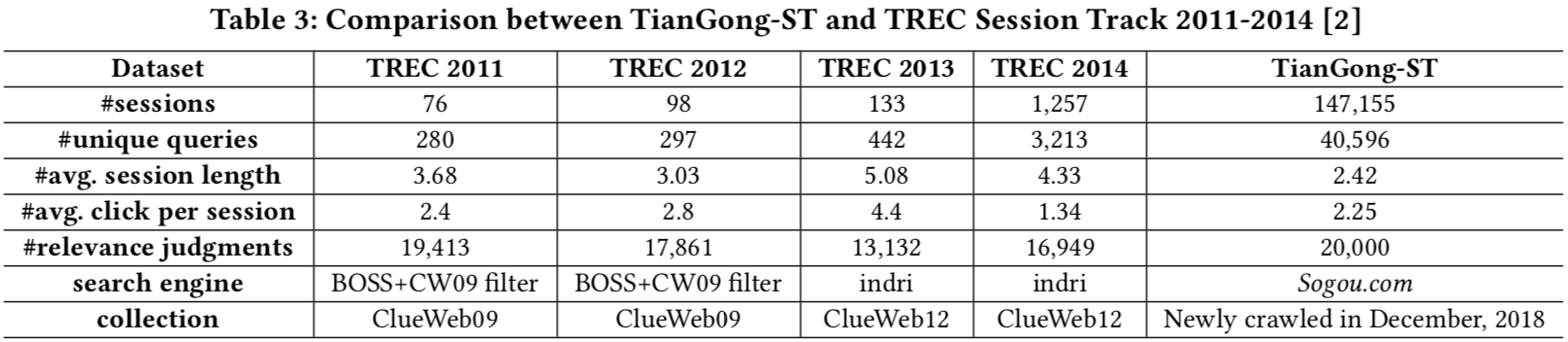
Basic statistics of TianGong-ST compared to some existing session datasets are as follows:
以下表格是TianGong-ST与一些已有的会话数据的统计量对比:
Dataset Organization
The session data is organized in a prettified XML format similar to TREC Session Tracks, as shown in the following.
TianGong-ST的会话数据按照TREC Session Tracks组织为XML格式,如下图所示:
<SogouSessionTrack2018>
<session num="348" starttime="1427889449.3">
<interaction num="2" starttime="1427889470.05">
<query>柯南国语版全集</query>
<query_id>q60819</query_id>
<results>
<result rank="1">
<url>http://www.iqiyi.com/dongman/mztkngyb.html</url>
<docid>d7292</docid>
<title>名侦探柯南 国语版-动漫动画-全集高清正版视频在线观看-爱奇艺</title>
<vtype>10000202#184</vtype>
<relevance>
<TACM>0.98156119246</TACM>
<PSCM>0.977745530311</PSCM>
<THCM>0.859149722736</THCM>
<UBM>0.399379760449</UBM>
<DBN>0.229812602511</DBN>
<POM>1.0</POM>
</relevance>
</result>
...
</results>
<clicked>
<click num="1" starttime="1427889474.44">
<rank>2</rank>
</click>
</clicked>
</interaction>
...
</session>
...
</SogouSessionTrack2018>
A session is consist of several search interactions together with a clicked-document list. Each interaction represents a search iteration where a user submits an independent query and receives top 10 documents from the search engine. For each round of interactions, the query text and query identifier are provided. For each document in the result list, the URL, document identifier, title, and six click-based relevance labels are given. In addition, the start timestamps for all sessions, interactions, and clicked documents are also presented to support dwell-time based models. Titles of Web pages that we fail to crawl are replaced by UNK.
一个会话由多个交互以及一个被点击的文档列表组成。每个交互表示会话中的一个回合:用户提交一个查询,而搜索引擎返回前10个相关文档。在每个交互回合中,我们提供了查询文本以及查询编码。对于在结果列表中的每个文档,我们提供了该文档的URL、编码、标题以及使用6种点击模型生成的弱相关性标签。另外,我们还提供了所有会话、交互回合以及被点击文档的开始时间戳,以便支持基于停留时间的模型。对于部分未能抓取的网页,其标题被替代为UNK。
Each file in the Web page set which contains a word sequence of the corresponding Web page contents, is named after the document identifier. Here we apply the open-sourced jiaba_fast tool for Chinese word segmentation.
网页集合中的每一个文件都包含了从相应网页正文提取的词语序列,并被命名为相应文档的编码。这里我们使用了开源工具包jieba_fast来进行中文分词。
As for the human label file, it contains the sample id, session id, query id, document id, the relevance label and the Web page validality variable (whether the Web page is valid), as follows:
对于人工标注文件,我们提供的信息包含采样id、会话id、查询id、文档id、相关性标签以及网页有效性,其格式如下:
1 1844 q2124 d19378 2 1
1 1844 q2124 d19375 0 0
1 1844 q2124 d19374 1 1
1 1844 q2124 d19377 2 1
1 1844 q2124 d19376 2 1
1 1844 q2124 d19371 2 1
1 1844 q2124 d19370 2 1
1 1844 q2124 d19373 1 1
1 1844 q2124 d19372 0 1
1 1844 q2124 d19369 2 1
How to get TianGong-ST
We provide a demo of TianGong-ST which contains 2 sessions to help researchers have a quick start. For the whole copy of the TianGong-ST dataset, you need to contact with us (thuir_datamanage@126.com). After signing an application forum online, we can send you the data.
我们提供了一份包含两个会话内容的TianGong-ST样例数据,可帮助研究者们快速上手。若希望获取TianGong-ST的所有数据,请通过邮件联系我们(thuir_datamanage@126.com),完成在线申请后即可获得。
Update – TianGong-ST 2.0
To enhance the research in more retrieval tasks, we provide an updated version of TianGong-ST – TianGong-ST 2.0. By relaxing some filtering rules, more sessions in the raw log data are supplemented. Differences between TianGong-ST 2.0 and the initial version are:
- More sessions and documents with high quality are available.
- For researchers’ convenience, the sessions are organized into the
txtformat, more details please refer to the correspondingREADME.txtfile. - Weak relevance labels generated by click models are deleted.
为了促进更多检索任务的研究,我们提供了一个更新版本的数据 —— TianGong-ST 2.0。通过适当放松原始日志的数据过滤条件,更多的会话被添加入数据集中。其中,TianGong-ST 2.0和初始版本之间的差别在于:
- 拥有更多数量的高质量会话和文档
- 为方便研究者处理,文档整理为
txt格式,具体格式详见相应说明文件 - 删除了由点击模型生成的弱相关性标签
Citation
If you use TianGong-ST in your research, please add the following bibtex citation in your references. A preprint of this paper can be found here TianGong-ST.
如果您在研究中使用了TianGong-ST,请将如下bibtex内容加入到您的引用列表中。关于TianGong-ST论文,您可以在此处找到。
@inproceedings{chen2019tian,
title={TianGong-ST: A New Dataset with Large-scale Refined Real-world Web Search Sessions},
author={Chen, Jia and Mao, Jiaxin and Liu, Yiqun and Zhang, Min and Ma, Shaoping},
booktitle={Proceedings of the 28th ACM International on Conference on Information and Knowledge Management},
year={2019},
organization={ACM}
}