Opensource 开源项目与数据
Toolkits
 ReChorus2.0Top-K Recommendation with Implicit Feedback
ReChorus2.0Top-K Recommendation with Implicit FeedbackReChorus2.0 is a modular and task-flexible PyTorch library for recommendation, especially for research purpose. It aims to provide researchers a flexible framework to implement various recommendation tasks, compare different algorithms, and adapt to diverse and highly-customized data inputs.
ReChorusTop-K Recommendation with Implicit FeedbackReChorus is a general PyTorch framework for Top-K recommendation with implicit feedback, especially for research purpose. It aims to provide a fair benchmark to compare different state-of-the-art algorithms. We hope this can partially alleviate the problem that different papers adopt non-comparable experimental settings, so as to form a “Chorus” of recommendation algorithms.
 ULTRAUnbiased Learning to Rank Algorithm
ULTRAUnbiased Learning to Rank AlgorithmULTRA is an Unbiased Learning To Rank Algorithms toolbox that provides a codebase for experiments and research on learning to rank with human annotated or noisy labels. With the unified data processing pipeline, ULTRA supports multiple unbiased learning-to-rank algorithms, online learning-to-rank algorithms, neural learning-to-rank models, as well as different methods to use and simulate noisy labels (e.g., clicks) to train and test different algorithms/ranking models
EasyRL4Rec is an easy-to-use library for Reinforcement Learning (RL) based Recommender Systems, covering five public datasets, three accessible simulator-based environments, comprehensive RL-based baselines, and unified evaluation protocols to make RL-based recommendation research easier to reproduce and compare.
A privacy-aware logging toolkit for running remote information retrieval user-study experiments, helping researchers collect interaction data from participants without compromising user privacy.
MemCraft is an OpenClaw memory integration plugin that connects major LLM memory baselines to OpenClaw, providing a local-first, reproducible, and extensible unified memory framework for both general users and researchers.
LegalKit is a practical and extensible evaluation toolkit for legal-domain Large Language Models. It unifies dataset adapters, model generation, offline JSON evaluation, and LLM-as-Judge scoring into a single workflow, with an optional lightweight Web UI for non-terminal users.
A clean, modular, and easy-to-use codebase developed for the SIGIR 2025 Tutorial on Dynamic and Parametric Retrieval-Augmented Generation, to reproduce, compare, and extend dynamic RAG methods such as DRAGIN (ACL 2024) and FLARE.
A toolkit developed for the SIGIR 2025 Tutorial on Dynamic and Parametric Retrieval-Augmented Generation, designed to help researchers and practitioners reproduce, compare, and extend Parametric RAG methods, specifically PRAG and DyPRAG.
Datasets
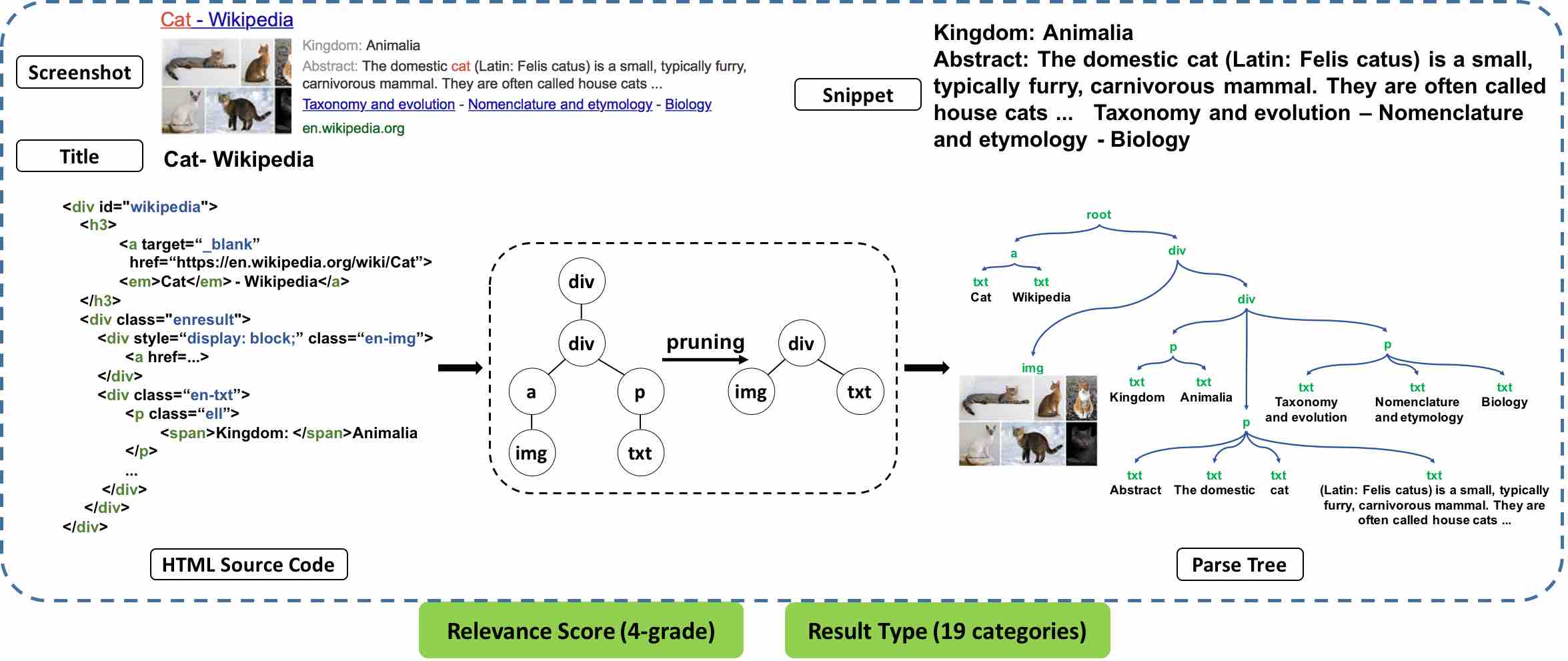

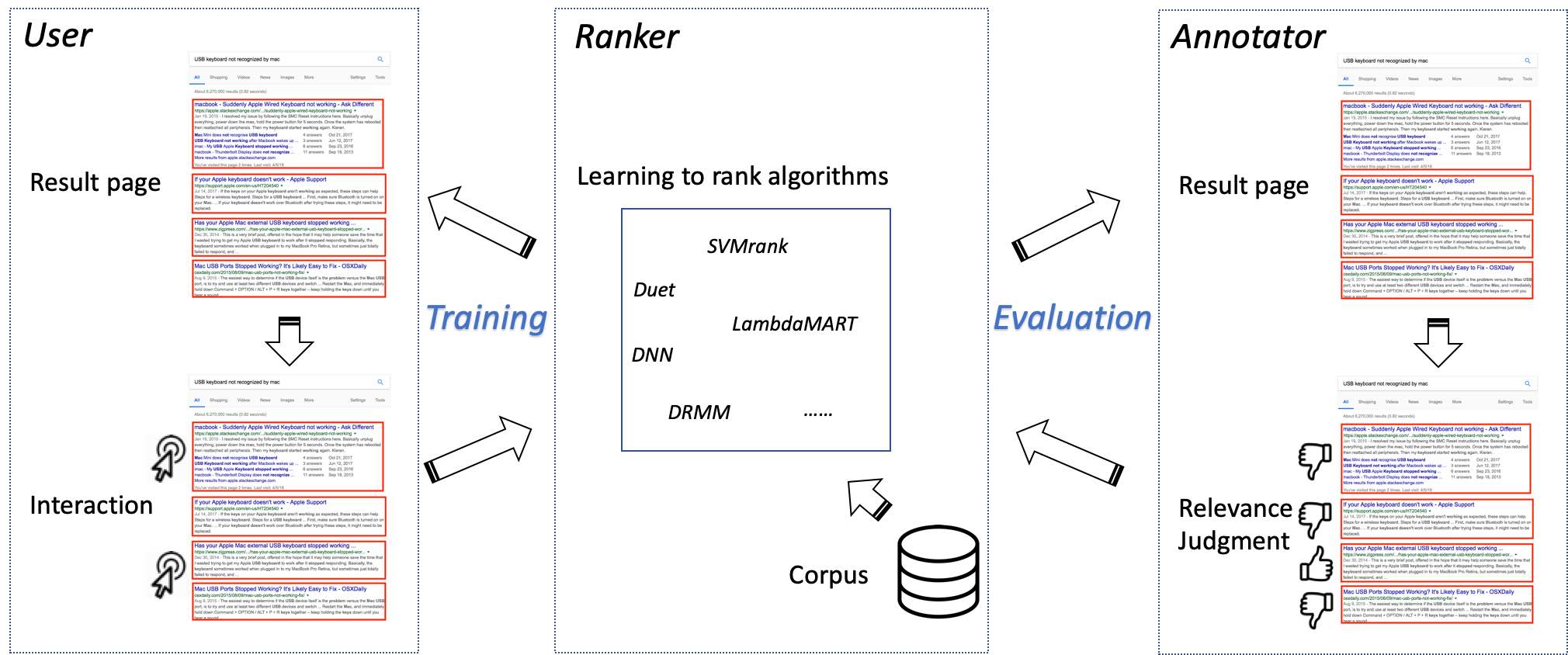
Code / Paper Implementations
HuggingFace Projects
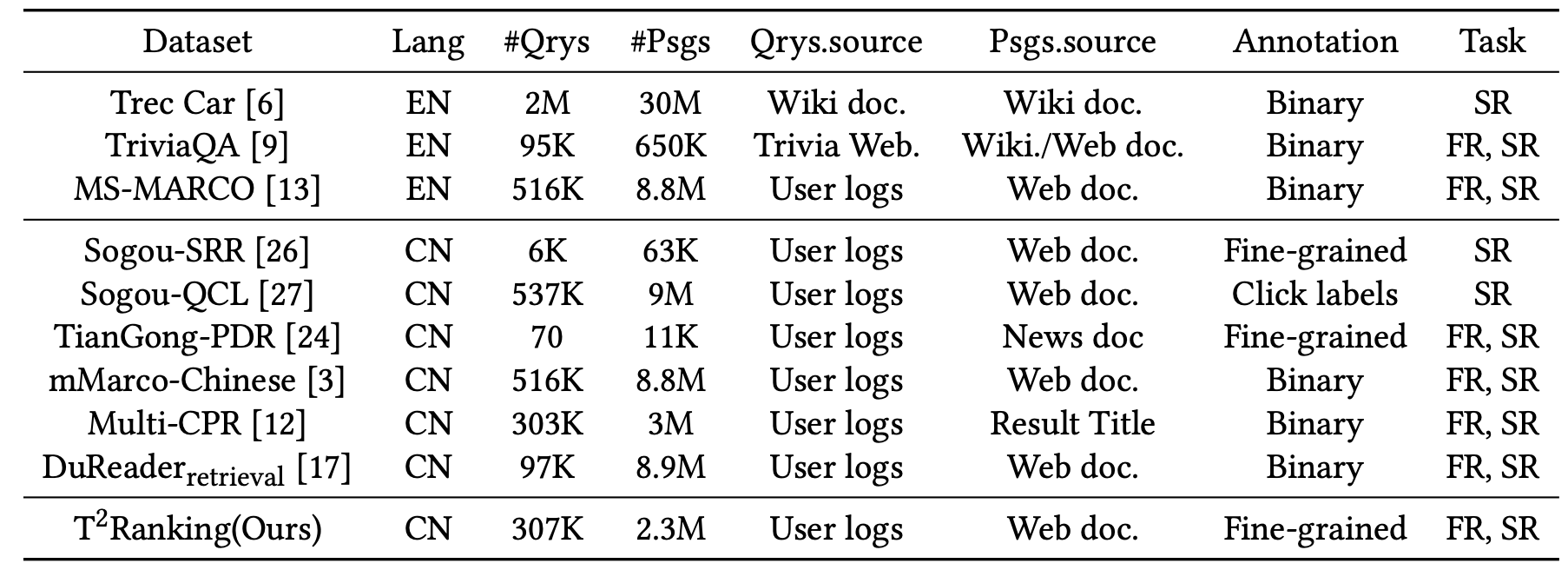
T2Rankinghuggingface.co/datasets/THUIR/T2RankingA large-scale Chinese benchmark for passage ranking with more than 300K queries and over 2M unique passages sampled from real-world search engines, distributed via the HuggingFace Datasets Hub.
 Qilinhuggingface.co/datasets/THUIR/Qilin
Qilinhuggingface.co/datasets/THUIR/QilinA large-scale multimodal dataset for search, recommendation, and Retrieval-Augmented Generation (RAG) research, built from app-level user sessions with rich query, interaction, and multimodal content data.
 MemoryBenchhuggingface.co/datasets/THUIR/MemoryBench
MemoryBenchhuggingface.co/datasets/THUIR/MemoryBenchA benchmark for evaluating memory and continual learning in LLM systems, testing whether they can learn from accumulated user feedback during service time. Accepted at ICML 2026 as a Spotlight paper.
 MemoryBench-Fullhuggingface.co/datasets/THUIR/MemoryBench-Full
MemoryBench-Fullhuggingface.co/datasets/THUIR/MemoryBench-FullAn extended version of the MemoryBench dataset with additional user feedback data and simulator settings.
 MemoryBench-Resultshuggingface.co/datasets/THUIR/MemoryBench-Results
MemoryBench-Resultshuggingface.co/datasets/THUIR/MemoryBench-ResultsAn artifact archive of published MemoryBench experiment runs, including model predictions, per-sample evaluation details, and aggregate summaries across multiple backbone models.
 AEOLLMhuggingface.co/datasets/THUIR/AEOLLM
AEOLLMhuggingface.co/datasets/THUIR/AEOLLMDatasets for the NTCIR-18 and NTCIR-19 Automatic Evaluation of LLMs (AEOLLM) tasks, supporting research on automatic evaluation methods for large language model outputs.
 AEOLLM Leaderboardhuggingface.co/spaces/THUIR/AEOLLM
AEOLLM Leaderboardhuggingface.co/spaces/THUIR/AEOLLMA live leaderboard Space tracking submissions to the NTCIR AEOLLM tasks for automatic evaluation of large language models.
 MetaSynhuggingface.co/datasets/THUIR/MetaSyn
MetaSynhuggingface.co/datasets/THUIR/MetaSynA dataset of 442 meta-analyses from the Nature Portfolio (2015-2024) paired with a retrieval corpus of 140K+ PubMed-indexed articles, built to benchmark LLM agent pipelines on the full meta-analysis workflow of retrieval, screening, extraction, and synthesis.
Special thanks to Shuqi Zhu for the initial construction of this page.